TL;DR: The glibc DNS bug (CVE-2015-7547) is unusually bad. Even Shellshock and Heartbleed tended to affect things we knew were on the network and knew we had to defend. This affects a universally used library (glibc) at a universally used protocol (DNS). Generic tools that we didn’t even know had network surface (sudo) are thus exposed, as is software written in programming languages designed explicitly to be safe. Who can exploit this vulnerability? We know unambiguously that an attacker directly on our networks can take over many systems running Linux. What we are unsure of is whether an attacker anywhere on the Internet is similarly empowered, given only the trivial capacity to cause our systems to look up addresses inside their malicious domains.
We’ve investigated the DNS lookup path, which requires the glibc exploit to survive traversing one of the millions of DNS caches dotted across the Internet. We’ve found that it is neither trivial to squeeze the glibc flaw through common name servers, nor is it trivial to prove such a feat is impossible. The vast majority of potentially affected systems require this attack path to function, and we just don’t know yet if it can. Our belief is that we’re likely to end up with attacks that work sometimes, and we’re probably going to end up hardening DNS caches against them with intent rather than accident. We’re likely not going to apply network level DNS length limits because that breaks things in catastrophic and hard to predict ways.
This is a very important bug to patch, and it is good we have some opportunity to do so.
It’s problematic that, a decade after the last DNS flaw that took a decade to fix, we have another one. It’s time we discover and deploy architectural mitigations for these sorts of flaws with more assurance than technologies like ASLR can provide. The hard truth is that if this code was written in JavaScript, it wouldn’t have been vulnerable. We can do better than that. We need to develop and fund the infrastructure, both technical and organizational, that defends and maintains the foundations of the global economy.
Click here if you’re a DNS expert and don’t need to be told how DNS works.
Click here if your interests are around security policy implications and not the specific technical flaw in question.
Update: Click here to learn how this issue compares to last year’s glibc DNS flaw, Ghost.
=====
Here is a galaxy map of the Internet. I helped the Opte project create this particular one.

And this galaxy is Linux – specifically, Ubuntu Linux, in a map by Thomi Richards, showing how each piece of software inside of it depends on each other piece.

There is a black hole at the center of this particular galaxy – the GNU C Standard Library, or glibc. And at this center, in this black hole, there is a flaw. More than your average or even extraordinary flaw, it’s affecting a shocking amount of code. How shocking?
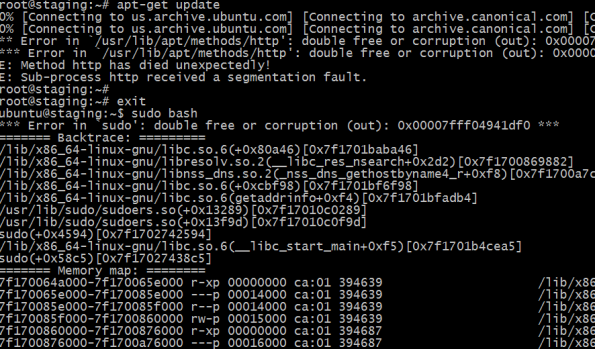
I’ve seen a lot of vulnerabilities, but not too many that create remote code execution in sudo. When DNS ain’t happy, ain’t nobody happy. Just how much trouble are we in?
We’re not quite sure.
Background
Most Internet software is built on top of Linux, and most Internet protocols are built on top of DNS. Recently, Redhat Linux and Google discovered some fairly serious flaws in the GNU C Library, used by Linux to (among many other things) connect to DNS to resolve names (like google.com) to IP addresses (like 8.8.8.8). The buggy code has been around for quite some time – since May 2008 – so it’s really worked its way across the globe. Full remote code execution has been demonstrated by Google, despite the usual battery of post-exploitation mitigations like ASLR, NX, and so on.
What we know unambiguously is that an attacker who can monitor DNS traffic between most (but not all) Linux clients, and a Domain Name Server, can achieve remote code execution independent of how well those clients are otherwise implemented. (Android is not affected.) That is a solid critical vulnerability by any normal standard.
Actionable Intelligence
Ranking exploits is silly. They’re not sports teams. But generally, what you can do is actually less important than who you have to be to do it. Bugs like Heartbleed, Shellshock, and even the recent Java Deserialization flaws ask very little of attackers – they have to be somewhere on a network that can reach their victims, maybe just anywhere on the Internet at large. By contrast, the unambiguous victims of glibc generally require their attackers to be close by.
You’re just going to have to believe me when I say that’s less of a constraint than you’d think, for many classes of attacker you’d actually worry about. More importantly though, the scale of software exposed to glibc is unusually substantial. For example:
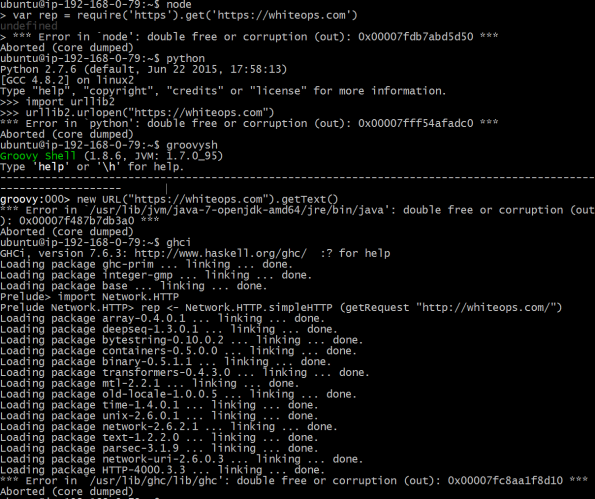
That’s JavaScript, Python, Java, and even Haskell blowing right up. Just because they’re “memory-safe” doesn’t mean their runtime libraries are, and glibc is the big one under Linux they all depend on. (Not that other C libraries should be presumed safe. Ahem.)
There’s a reason I’m saying this bug exposes Linux in general to risk. Even your paranoid solutions leak DNS – you can route everything over a VPN, but you’ve still got to discover where you’re routing it to, and that’s usually done with DNS. You can push everything over HTTPS, but what’s that text after the https://? It’s a DNS domain.
Importantly, the whole point of entire sets of defenses is that there’s an attacker on the network path. That guy just got a whole new set of toys, against a whole new set of devices. Everyone protects apache, who protects sudo?
So, independent of whatever else may be found, Florian, Fermin, Kevin, and everyone else at Redhat and Google did some tremendous work finding and repairing something genuinely nasty. Patch this bug with extreme prejudice. You’ll have to reboot everything, even if it doesn’t get worse.
It might get worse.
The Hierarchy
DNS is how this Internet (there were several previous attempts) achieves cross-organizational interoperability. It is literally the “identity” layer everything else builds upon; everybody can discover Google’s mail server, but only Google can change it. Only they have the delegated ownership rights for gmail.com and google.com. Those rights were delegated by Verisign, who owns .com, who themselves received that exclusive delegation from ICANN, the Internet Corporation for Assigned Names and Numbers.
The point is not to debate the particular trust model of DNS. The point is to recognize that it’s not just Google who can register domains; attackers can literally register badguy.com and host whatever they want there. If a DNS vulnerability could work through the DNS hierarchy, we would be in a whole new class of trouble, because it is just extraordinarily easy to compel code that does not trust you to retrieve arbitrary domains from anywhere in the DNS. You connect to a web server, it wants to put your domain in its logs, it’s going to look you up. You connect to a mail server, it wants to see if you’re a spammer, it’s going to look you up. You send someone an email, they reply. How does their email find you? Their systems are going to look you up.
It would be unfortunate if those lookups led to code execution.
Once, I gave a talk to two hundred software developers. I asked them, how many of you depend on DNS? Two hands go up. I then asked, how many of you expect a string of text like google.com to end up causing a connection to Google? 198 more hands. Strings containing domain names happen all over the place in software, in all sorts of otherwise safe programming languages. Far more often than not, those strings not only find their way to a DNS client, but specifically to the code embedded in the operating system (the one thing that knows where the local Domain Name Server is!). If that embedded code, glibc, can end up receiving from the local infrastructure traffic similar enough to what a full-on local attacker would deliver, we’re in a lot more trouble. Many more attackers can cause lookups to badguy.com, than might find themselves already on the network path to a target.
Domain Name Servers
Glibc is what is known as a “stub resolver”. It asks a question, it gets an answer, somebody else actually does most of the work running around the Internet bouncing through ICANN to Verisign to Google. These “somebody elses” are Domain Name Servers, also known as caching resolvers. DNS is an old protocol – it dates back to 1983 – and comes from a world where bandwidth was so constrained that every bit mattered, even during protocol design. (DNS got 16 bits in a place so TCP could get 32. “We were young, we needed the bits” was actually a thing.) These caching resolvers actually enforce a significant amount of rules upon what may or may not flow through the DNS. The proof of concept delivered by Google essentially delivers garbage bytes. That’s fine on the LAN, where there’s nothing getting in the way. But name servers can essentially be modeled as scrubbing firewalls – in most (never all) environments, traffic that is not protocol compliant is just not going to reach stubs like glibc. Certainly that Google Proof of Concept isn’t surviving any real world cache.
Does that mean nothing will? As of yet, we don’t actually know. According to Redhat:
A back of the envelope analysis shows that it should be possible to write correctly formed DNS responses with attacker controlled payloads that will penetrate a DNS cache hierarchy and therefore allow attackers to exploit machines behind such caches.
I’m just going to state outright: Nobody has gotten this glibc flaw to work through caches yet. So we just don’t know if that’s possible. Actual exploit chains are subject to what I call the MacGyver effect. For those unfamiliar, MacGyver was a 1980’s television show that showed a very creative tinkerer building bombs and other such things with tools like chocolate. The show inspired an entire generation of engineers, but did not lead to a significant number of lost limbs because there was always something non-obvious and missing that ultimately prevented anything from working. Exploit chains at this layer are just a lot more fragile than, say, corrupted memory. But we still go ahead and actually build working memory corruption exploits, because some things are just extraordinarily expensive to fix, and so we better be sure there’s unambiguously a problem here.
At the extreme end, there are discussions happening about widespread DNS filters across the Internet – certainly in front of sensitive networks. Redhat et al did some great work here, but we do need more than the back of the envelope. I’ve personally been investigating cache traversal variants of this attack. Here’s what I can report after a day.
Cache Attacks
Somewhat simplified, the attacks depend on:.
- A buffer being filled with about 2048 bytes of data from a DNS response
- The stub retrying, for whatever reason
- Two responses ultimately getting stacked into the same buffer, with over 2048 bytes from the wire
The flaw is linked to the fact that the stack has two outstanding requests at the same time – one for IPv4 addresses, and one for IPv6 addresses. Furthermore DNS can operate over both UDP and TCP, with the ability to upgrade from the former to the latter. There is error handling in DNS, but most errors and retries are handled by the caching resolver, not the stub. That means any weird errors just cause the (safer, more properly written) middlebox to handle the complexity, reducing degrees of freedom for hitting glibc.
Given that rough summary of the constraints, here’s what I can report. This CVE is easily the most difficult to scope bug I’ve ever worked on, despite it being in a domain I am intimately familiar with. The trivial defenses against cache traversal are easily bypassable; the obvious attacks that would generate cache traversal are trivially defeated. What we are left with is a morass of maybe’s, with the consequences being remarkably dire (even my bug did not yield direct code execution). Here’s what I can say at present time, with thanks to those who have been very generous with their advice behind the scenes.
- The attacks do not need to be garbage that could never survive a DNS cache, as they are in the Google PoC. It’s perfectly legal to have large A and AAAA responses that are both cache-compatible and corrupt client memory. I have this working well.
- The attacks do not require UDP or EDNS0. Traditional DNS has a 512 byte limit, notably less than the 2048 bytes required. Some people (including me) thought that since glibc doesn’t issue the EDNS0 request that declares a larger buffer, caching resolvers would not provide sufficient data to create the required failure state. Sure, if the attack was constrained to UDP as in the Google PoC. But not only does TCP exist, but we can set the tc “Truncation” bit to force an upgrade to the protocol with more bandwidth. This most certainly does traverse caches.
- There are ways of making the necessary retry occur, even through TCP. We’re still investigating them, as it’s a fundamental requirement for the attack to function. (No retry, no big write to small buf.)
Where I think we’re going to end up, around 24 (straight) hours of research in, is that some networks are going to be vulnerable to some cache traversal attacks sometimes, following the general rule of “attacks only get better”. That rule usually only applies to crypto vulns, but on this half-design half-implementation vuln, we get it here too. This is in contrast to the on-path attackers, who “just” need to figure out how to smash a 2016 stack and away they go. There’s a couple comments I’d like to make, which summarize down to “This may not get nasty in days to weeks, but months to years has me worried.”
- Low reliability attacks become high reliability in DNS, because you can just do a lot of them very quickly. Even without forcing an endpoint to hammer you through some API, name servers have all sorts of crazy corner cases where they blast you with traffic quickly, and stop only when you’ve gotten data successfully in their cache. Load causes all sorts of weird and wooly behavior in name servers, so proving something doesn’t work in the general case says literally nothing about edge case behavior.
- Low or no Time To Live (TTL) mean the attacker can disable DNS caching, eliminating some (but not nearly all) protections one might assume caching creates. That being said, not all name servers respect a zero TTL, or even should.
- If anything is going to stop actual cache traversing exploitability, it’s that you just have an absurd amount more timing and ordering control directly speaking to clients over TCP and UDP, than you do indirectly communicating with the client through a generally protocol enforcing cache. That doesn’t mean there won’t be situations where you can cajole the cache to do your bidding, even unreliably, but accidental defenses are where we’re at here.
- Those accidental defenses are not strong. They’re accidents, in the way DNS cache rules kept my own attacks from being discovered. Eventually we figured out we could do other things to get around those defenses and they just melted in seconds. The possibility that a magic nasty payload pushes a major namesever or whatever into some state that quickly and easily knocks stuff over, on the scale of months to years, is non-trivial.
- Stub resolvers are not just weak, they’re kind of designed to be that way. The whole point is you don’t need a lot of domain specific knowledge (no pun intended) to achieve resolution over DNS; instead you just ask a question and get an answer. Specifically, there’s a universe of DNS clients that don’t randomize ports (or even transaction id’s). You really don’t want random Internet hosts poking your clients spoofing your name servers. Protecting against spoofed traffic on the global Internet is difficult; preventing traffic spoofing from outside networks using internal addresses is on the edge of practicality.
Let’s talk about suggested mitigations, and then go into what we can learn policy-wise from this situation.
Length Limits Are Silly Mitigations
No other way to say it. Redhat might as well have suggested filtering all AAAA (IPv6) records – might actually be effective, as it happens, but it turns out security is not the only engineering requirement at play. DNS has had to engineer several mechanisms for sending more than 512 bytes, and not because it was a fun thing to do on a Saturday night. JavaScript is not the only thing that’s gotten bigger over the years; we are putting more and more in there and not just DNSSEC signatures either. What is worth noting is that IT, and even IT Security, has actually learned the very very hard way not to apply traditional firewalling approaches to DNS. Basically, as a foundational protocol it’s very far away from normal debugging interfaces. That means, when something goes wrong – like, somebody applied a length limit to DNS traffic who was not themselves a DNS engineer – there’s this sudden outage that nobody can trace for some absurd amount of time. By the time the problem gets traced…well, if you ever wondered why DNS doesn’t get filtered, that is why.
And ultimately, any DNS packet filter is a poor version of what you really want, which is an actual protocol enforcing scrubbing firewall, i.e. a name server that is not a stub, though it might be a forwarder (meaning it enforces all the rules and provides a cache, but doesn’t wander around the Internet resolving names). My expectations for mitigations, particularly as we actually start getting some real intelligence around cache traversing glibc attacks, are:
- We will put more intelligent resolvers on more devices, such that glibc is only talking to the local resolver not over the network, and
- Caching resolvers will learn how to specially handle the case of simultaneous A and AAAA requests. If we’re protected from traversing attacks it’s because the attacker just can’t play a lot of games between UDP and TCP and A and AAAA responses. As we learn more about when the attacks can traverse caches, we can intentionally work to make them not.
Local resolvers are popular anyway, because they mean there’s a DNS cache improving performance. A large number of embedded routers are already safe against the verified on-path attack scenario due to their use of dnsmasq, a common forwarding cache.
Note that technologies like DNSSEC are mostly orthogonal to this threat; the attacker can just send us signed responses that he in particular wants to break us. I say mostly because one mode of DNSSEC deployment involves the use of a local validating resolver; such resolvers are also DNS caches that insulate glibc from the outside world.
There is the interesting question of how to scan and detect nodes on your network with vulnerable versions of glibc. I’ve been worried for a while we’re only going to end up fixing the sorts of bugs that are aggressively trivial to detect, independent of their actual impact to our risk profiles. Short of actually intercepting traffic and injecting exploits I’m not sure what we can do here. Certainly one can look for simultaneous A and AAAA requests with identical source ports and no EDNS0, but that’s going to stay that way even post patch. Detecting what on our networks still needs to get patched (especially when ultimately this sort of platform failure infests the smallest of devices) is certain to become a priority – even if we end up making it easier for attackers to detect our faults as well.
If you’re looking for actual exploit attempts, don’t just look for large DNS packets. UDP attacks will actually be fragmented (normal IP packets cannot carry 2048 bytes) and you might forget DNS can be carried over TCP. And again, large DNS replies are not necessarily malicious.
And thus, we end up at a good transition point to discuss security policy. What do we learn from this situation?
The Fifty Thousand Foot View
Patch this bug. You’ll have to reboot your servers. It will be somewhat disruptive. Patch this bug now, before the cache traversing attacks are discovered, because even the on-path attacks are concerning enough. Patch. And if patching is not a thing you know how to do, automatic patching needs to be something you demand from the infrastructure you deploy on your network. If it might not be safe in six months, why are you paying for it today?
It’s important to realize that while this bug was just discovered, it’s not actually new. CVE-2015-7547 has been around for eight years. Literally, six weeks before I unveiled my own grand fix to DNS (July 2008), this catastrophic code was committed.
Nobody noticed.
The timing is a bit troublesome, but let’s be realistic: there’s only so many months to go around. The real issue is it took almost a decade to fix this new issue, right after it took a decade to fix my old one (DJB didn’t quite identify the bug, but he absolutely called the fix). The Internet is not less important to global commerce than it was in 2008. Hacker latency continues to be a real problem.
What maybe has changed over the years is the strangely increasing amount of talk about how the Internet is perhaps too secure. I don’t believe that, and I don’t believe anyone in business (or even with a credit card) does either. But the discussion on cybersecurity seems dominated by the necessity of insecurity. Did anyone know about this flaw earlier? There’s absolutely no way to tell. We can only know we need to be finding these bugs faster, understanding these issues better, and fixing them more comprehensively.
We need to not be finding bugs like this, eight years from now, again.
(There were clear public signs of impending public discovery of this flaw, so do not take my words as any form of criticism for the release schedule of this CVE.)
My concerns are not merely organizational. I do think we need to start investing significantly more in mitigation technologies that operate before memory corruption has occurred. ASLR, NX, Control Flow Guard – all of these technologies are greatly impressive, at showing us who our greatly impressive hackers are. They’re not actually stopping code execution from being possible. They’re just not.
Somewhere between base arithmetic and x86 is a sandbox people can’t just walk in and out of. To put it bluntly, if this code had been written in JavaScript – yes, really – it wouldn’t have been vulnerable. Even if this network exposed code remained in C, and was just compiled to JavaScript via Emscripten, it still would not have been vulnerable. Efficiently microsandboxing individual codepaths is a thing we should start exploring. What can we do to the software we deploy, at what cost, to actually make exploitation of software flaws actually impossible, as opposed to merely difficult?
It is unlikely this is the only platform threat, or even the only threat in glibc. With the Internet of Things spreading extraordinarily, perhaps it’s time to be less concerned about being able to spy on every last phone call and more concerned about how we can make sure innovators have better environments to build upon. I’m not merely talking about the rather “frothy” software stacks adorning the Internet of Things, with Bluetooth and custom TCP/IP and so on. I’m talking about maintainability. When we find problems — and we will — can we fix them? This is a problem that took Android too long to start seriously addressing, but they’re not the only ones. A network where devices eventually become existential threats is a network that eventually ceases to exist. What do we do for platforms to guarantee that attack windows close? What do we do for consumers and purchasing agents so they can differentiate that which has a maintenance warranty, and that which does not?
Are there insurance structures that could pay out, when a glibc level patch needs to be rolled out?
There’s a level of maturity that can be brought to the table, and I think should. There are a lot of unanswered questions about the scope of this flaw, and many others, that perhaps neither vendors nor volunteer researchers are in the best position to answer. We can do better building the secure platforms of the future. Let’s start here.
Source: DanKaminisky
Source Link: https://dankaminsky.com/2016/02/20/skeleton/